
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- PT 운동
- 논문 리뷰
- 덤벨운동
- 코드
- 코딩테스트
- 다이어트
- 건강
- 개인 피티
- 영화 비평
- 코테준비
- github
- 디버깅
- 체스트프레스
- 데드리프트
- 바디프로필
- 라섹 수술 후기
- 코테 공부
- 암풀다운
- 티스토리챌린지
- 프로그래머스
- 운동
- 하체운동
- 개인 운동
- Knowledge Tracing
- 바프준비
- 오블완
- 개인 PT
- 개발자
- 연구 시작
- pytorch
- Today
- Total
치즈의 AI 녹이기
모델 학습을 개선하는 4가지 테크닉 본문
1. torch.cuda.amp 활용하기
일부 작업에 대하여 float32에서 float16으로(또는 반대) 바꾸어 각 연산을 적절한 데이터 유형과 일치시킴으로써 학습 속도를 좀 더 빠르게 할 수 있다.
autocast(torch.cuda.amp와 동일)은 네트워크의 순방향 패스(forward + loss)에만 적용되어야 한다.

2. Gradient Accumulation
gradient를 특정 배치 주기까지 모았다가 한번에 업데이트하여 적은 메모리 환경에서 작은 배치사이즈로 큰 배치사이즈를 사용하는 효과를 기대한다. 큰 배치사이즈를 사용함으로써 학습 시 정보의 노이즈를 제거하고 더 나은 gradient descent를 수행할 수 있다.
3. Gradient Clipping
gradient exploding을 방지하여 학습의 안정화를 도모할 수 있다.
gradient가 일정 threshold를 넘어가면 gradient의 L2 norm으로 나눠준다.
learning rate를 작게 하는 것과 비교했을 때와 같은 효과를 얻는다.
4. Stochastic Weight Averaging (SWA)
시간에 흐름에 따라 다른 weight을 가진 똑같은 모델을 ensembling하는 방법이다.
학습 파라미터 w 외에 weight_swa을 따로 저장하여 일정 주기마다 weight을 average하여 weight_swa에 업데이트한다.

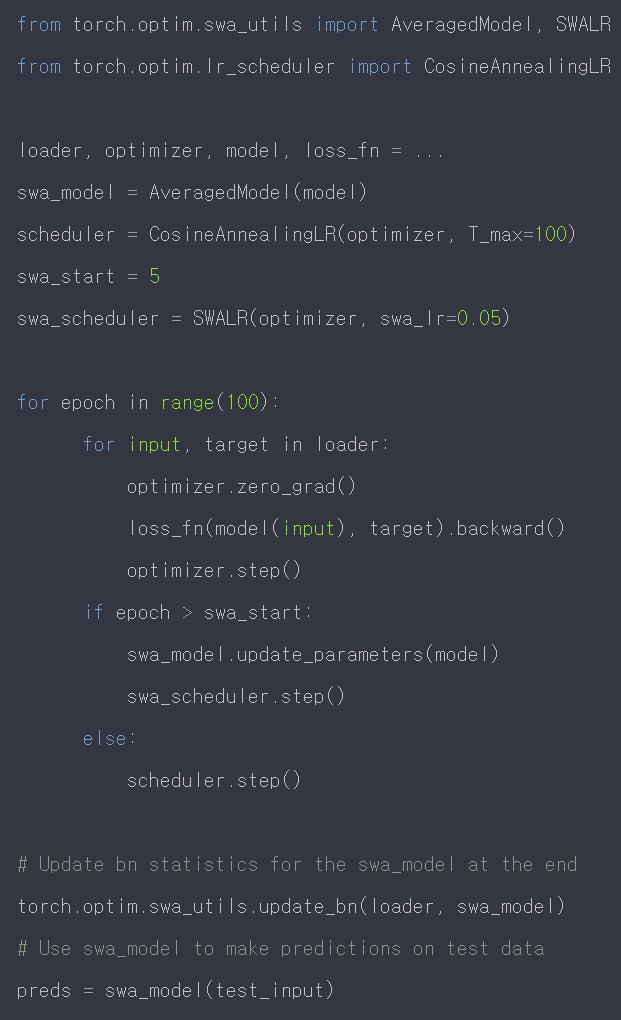
torch SWA 사용하기 :
https://runebook.dev/ko/docs/pytorch/optim
PyTorch - torch.optim - torch.optim 은 다양한 최적화 알고리즘을 구현하는 패키지입니다. 가장 일반적으
torch.optim 은 다양한 최적화 알고리즘을 구현하는 패키지입니다. 가장 일반적으로 사용되는 방법은 이미 지원되고 있으며 인터페이스는 충분히 일반적이므로 향후 더 복잡한 방법도 쉽게 통합
runebook.dev
SWA 구현 GITHUB :
https://github.com/timgaripov/swa/blob/master/train.py
GitHub - timgaripov/swa: Stochastic Weight Averaging in PyTorch
Stochastic Weight Averaging in PyTorch. Contribute to timgaripov/swa development by creating an account on GitHub.
github.com
SWA 참고 링크:
Stochastic Weight Averaging — a New Way to Get State of the Art Results in Deep Learning
Update: you can now enjoy this post on my personal blog, where math typography is much better (Medium doesn’t support math rendering…
towardsdatascience.com
'인공지능 대학원생의 생활 > 구글링' 카테고리의 다른 글
| docker: Error response from daemon: could not select device driver "" with capabilities: [[gpu]]. (0) | 2021.12.18 |
|---|---|
| Permission denied (0) | 2021.12.18 |
| Knowledge Distillation (0) | 2021.10.28 |
| Beam Search (0) | 2021.10.28 |
| Git에 requirements.txt 생성하기 (0) | 2021.07.27 |



