

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- github
- Knowledge Tracing
- 덤벨운동
- 디버깅
- 코딩테스트
- 프로그래머스
- 개인 피티
- 바프준비
- 영화 비평
- 데드리프트
- 개발자
- 바디프로필
- PT 운동
- 운동
- 체스트프레스
- 코테준비
- 연구 시작
- 개인 PT
- 다이어트
- 코드
- 논문 리뷰
- 티스토리챌린지
- 건강
- 암풀다운
- 라섹 수술 후기
- pytorch
- 개인 운동
- 코테 공부
- 하체운동
- 오블완
- Today
- Total
치즈의 AI 녹이기
Triplet Loss 본문
오늘은 Triplet Loss에 대해 다뤄보도록 합니다.
Siamese Network
classification task를 풀다보면, class imbalance 문제에 직면하게 됩니다. 어떤 클래스는 데이터의 개수가 매우 많고, 반대로 어떤 클래스는 데이터의 개수가 부족할 수 있습니다.
One-Shot Learning은 각 클래스를 학습하기 위해 클래스마다 하나씩의 데이터를 이용하는 방법을 제안합니다.
Siamese Network는 이러한 one-shot learning을 가능하게 하는 딥러닝 모델입니다.

Siamese Network는 한 개의 Convolution Net을 가지고 두 개의 이미지로 이루어진 한 쌍을 인풋으로 넣어줍니다.
그러면 featuremap(또는 embedding) 한 쌍이 아웃풋으로 출력될 것입니다.
이 두 개의 출력 값 사이의 cosine distance를 구한 후, sigmoid를 거쳐 0과 1사이의 확률값을 도출하도록 합니다.
결과값이 0에 가까울수록 두 이미지가 서로 다른 이미지임을 나타내고,
1에 가까울 수록 서로 비슷한 이미지임을 나타냅니다.
결국, 각 클래스마다 하나의 이미지만 가지고 있어도 클래스 간 이미지의 유사성과 차별성을 학습해나갈 수 있게 됩니다.
Triplet Loss
논문 FaceNet: A Unified Embedding for Face Recognition and Clustering에서 소개된 Triplet loss는 학습과정에서 두 개의 인풋이 아닌 세 개의 인풋 데이터를 모델에 넣습니다.
각각의 인풋을 Anchor, Positive, Negative라고 합니다.
- Anchor : Positive와 Negative의 기준. 아무 인풋 데이터나 들어올 수 있습니다.
- Positive : Anchor을 기준으로 Anchor과 같은 클래스에 속한 데이터가 들어옵니다.
- Negative : Anchor을 기준으로 Anchor과 다른 클래스에 속한 데이터가 들어옵니다.
Hard Positive와 Hard Negative도 아래에서 언급되기 때문에 먼저 설명합니다.
- Hard Positive : Positive이면서 Anchor와 가장 유사한 데이터가 들어옵니다.
- Hard Negative : Negative이면서 Anchor와 가장 유사한 데이터가 들어옵니다.


- x^a : anchor input
- x^p : positive input
- x^n : negative input
- α : anchor를 기준으로 positive와 negative 거리 사이의 허용 margin
- d : Euclidean Distance
이 loss function은 anchor와 positive 사이의 거리 d(a,p)는 가깝게하고, anchor와 negative 사이의 거리 d(a,n)는 멀게 만들어줍니다.
margin α의 역할은 d(a,p) = d(a,n) 이거나 d(a,p) <= d(a,n) 처럼 거리 차이가 아주 미미할 경우, loss function에서 d(a,p) < d(a,n)와 같은 취급을 받으며 학습이 제대로 이루어 지지 않는 문제를 보완해줍니다.
아래 그림은 범위마다 달라지는 negative sample의 난도(hard-easy)를 표시한 것입니다.
d(a,p) + α < d(a,n) 의 관점에서 보면 이해가 되실 겁니다.

논문에서는 학습 수렴을 위해 hard triplets을 적절하게 선택하여 식에 적용해야 한다고 말합니다.
hard triplets이란, 위에서 설명드린 hard positive와 hard negative입니다.
즉, a가 주어졌을 때, argmax(d(a,p)) 이면서 argmin(d(a,n))이 될 수 있는 p와 n을 뽑는 것이 이상적이라고 말합니다.
다만, 이상적인 p와 n을 뽑는 과정에서 모든 학습 데이터에 대해 탐색하는 것은 너무 시간이 오래 걸리는 문제가 있습니다. 따라서 논문에서는 다음과 같은 해결책을 제시하는데, 여전히 한계점이 있어보이네요;
- 특정 step 마다 최신에 저장된 모델을 불러와 subset 데이터에 대해서 hard sampling 하기.
- minibatch 안에서 hard sampling 하기 (논문에서 채택한 방법)
논문에서는 minibatch마다 약 40개의 서로 다른 anchor 데이터가 존재하도록 데이터를 분배하고, 나머지를 랜덤 negative sample로 채웠습니다.
그 다음, 가능한 모든 경우의 anchor-positive 쌍을 사용하고 hard negative sampling을 했다고 합니다.
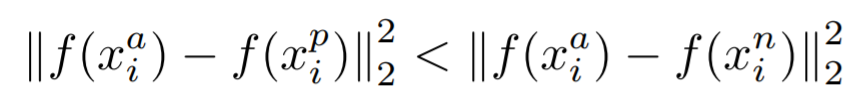
hard negative sample을 뽑는 기준은 위와 같은데, d(a,p) < d(a,n)라는 조건을 만족하는 것입니다.
α > d(a,n) - d(a,p) 의 관점에서 보면, 두 거리 간의 차이가 margin(α) 내에 있기 때문에 n이 a에 가까워지게 됩니다.
즉, negative가 positive보다 anchor로부터 멀리 떨어져 있으면서 여전히 두 distance의 차이가 margin(α) 내에 있는 상황을 뜻합니다.
이런 방법을 semi-hard sampling이라고 했는데, 이렇게 하는 것이 가장 hard한 negative sample을 선택했을 때 훈련 초기에 bad local minima에 빠지는 것을 완화한다고 합니다.
참고 링크 : https://medium.com/vitrox-publication/understanding-circle-loss-bdaa576312f7
'인공지능 대학원생의 생활 > 구글링' 카테고리의 다른 글
| 대용량 파일 압축 풀기 (tar.gz) (0) | 2021.07.20 |
|---|---|
| 구글 드라이브 대용량 파일을 터미널에서 바로 다운받기 (0) | 2021.07.12 |
| Metric Learning (0) | 2021.07.08 |
| Batch normalization vs Layer normalization (0) | 2021.06.24 |
| Weight decay (0) | 2021.06.24 |



